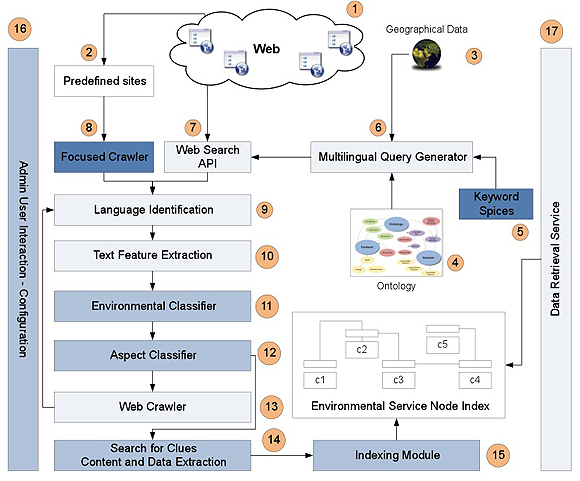
Environmental Service Node Discovery The objective is to research and develop environmental node discovery technologies that facilitate the search and profiling of service nodes in the web. This objective implies in particular the development of an environmental service node indexer that uses an optimized general purpose search engine to retrieve environmental service node pages and extract the relevant profile characteristics from them.
We address the discovery of environmental nodes as a domain specific search problem. Based on the state-of-the-art in the field, an architecture of the module for the discovery, retrieval and indexing of environmental nodes has been designed. To realize the architecture, we develop and integrate several components, which are tuned in order to deal with environmental information.
The architecture follows a hybrid approach: the first set of initial results is produced with the aid of a machine learning-based focused crawler, while the second set by querying a general purpose search engine. Below, the pipeline of the modules 1→2→8 reflects the procedure of discovering nodes by using a focused crawler, and the pipeline 1→5→6→7 the procedure based on general purpose search engines using keyword spices.
The formulation of multilingual queries is semi-automatic (as it supports the administrative user intervention) and it is based both on terms retrieved from the environmental ontology and geographical information from the web, while the translation is achieved with the aid of several translation tools. These queries are further expanded with the aid of keyword spices (i.e. domain specific keywords generated with the aid supervised machine learning techniques). The initial results are post-processed by employing language identification techniques, machine learning based classification and website crawling. The classification task includes the generation of textual features using a bag of words approach and the implementation of support vector machine classifiers trained to identify environmental websites. Finally, the information is extracted using content distillation techniques developed in WP4 and indexed in a GIS compatible repository, which supports textual, numerical and spatial indexing.
In an attempt to optimize and adjust the aforementioned techniques to our needs, we employ several components that could be used for post processing and analysis of environmental nodes, since it is essential that the final nodes provide specific type of information that will be extracted in the module “Content and Data Extraction” (14). Initially the retrieved websites pass through a Language Identification component (9), which is prerequisite for performing text analysis. Then, the post-processing procedure includes a text feature extraction step (10), in which the key-phrases of the web page are extracted taking into account the language of the page, and a classification step (11, 12), in which the relevant nodes are identified. The next step includes the crawling (13) of each node that has been characterized as relevant in order to retrieve the rest webpages of the site. For the new pages the same post-processing procedure is repeated. Then, each of the nodes (i.e. web pages) found is searched for environmental clues (14) and the data, which are of importance, are extracted (i.e. the environmental aspects reported and their values). The next step refers to the indexing (15) of the retrieved information in the repository with the aim of storing effectively the extracted information and respond in a fast and accurate way to the users requests. As this procedure is realized off line we need continuously accessing the indexed nodes in specified time intervals in order to update the environmental measurements. Finally, the Data Retrieval Service (DRS) (17) serves as the interface, through which other services or individuals can retrieve the information inside the Environmental Node Repository.
Future work will include the implementation of the final version of the modules, as well as a more detailed evaluation of the final pipeline. In that way we will be able to conclude which of the involved techniques are playing the most important role and provide the better results. Depending on the results we could also investigate several improvements of the involved techniques as for instance the exploitation of visual information and the administrative user feedback. On the one hand, the generation of visual features could possible improve the classification by considering a more extended lexicon enhanced by visual words. On the other, the administrative user feedback could be exploited for automatically creating training sets for classification and keyword spice generation tasks.
CONTACT: Stefanos Vrochidis <stefanos@iti.gr>